 Early in my career, I was asked by a large scientific society to write a report for them that compared year-over-year and month-over-month membership renewal numbers. They were running a SQL-based association management system (AMS) so I embarked on a journey to write a complex stored procedure to support a Crystal Report. For those of you who have experience writing stored procedures, I had to employ many temporary tables and While Loops to achieve the desired outcome.
Early in my career, I was asked by a large scientific society to write a report for them that compared year-over-year and month-over-month membership renewal numbers. They were running a SQL-based association management system (AMS) so I embarked on a journey to write a complex stored procedure to support a Crystal Report. For those of you who have experience writing stored procedures, I had to employ many temporary tables and While Loops to achieve the desired outcome.
When I completed the effort, I proudly presented my “masterpiece” to the client and they were very pleased with the work – for about 1 day. For some strange reason, the results for the prior year changed on day 2. I was confounded. I spent several hours proofing out my work and then had the duh… moment – data constantly changes in a transactional system, which affects the history of the data. Yikes! The report was never going to work unless the data was transferred and stored somewhere else where it couldn’t change. That was a hard way to learn what is actually a pretty simple concept.
Transactional databases, which are the foundation of all the major AMS systems in the market, are not generally architected to store a complete picture of history. While certain historical data elements may be kept, it would be a burden to the system to store the history of all changes. And, that is not the purpose of a transactional database. Instead, its primary role is to capture all database activity and provide a robust and fast transactional experience (e.g. registering for an event). Essentially, operational systems do a reasonably good job at telling you what is going on right now but struggle to provide historical and trend analysis.
The answer is a data strategy called snapshotting. While snapshotting can conceivably be done on a monthly, yearly or even daily rotation of a transactional database, AMS systems are not constructed to load and display multiple versions of the system, and the data storage schema of a transactional system is not optimized for super-fast reporting performance. Instead, a state-of-the-art data analytics solution like Nucleus is architected specifically to effectively store an unlimited number of versions of your data.
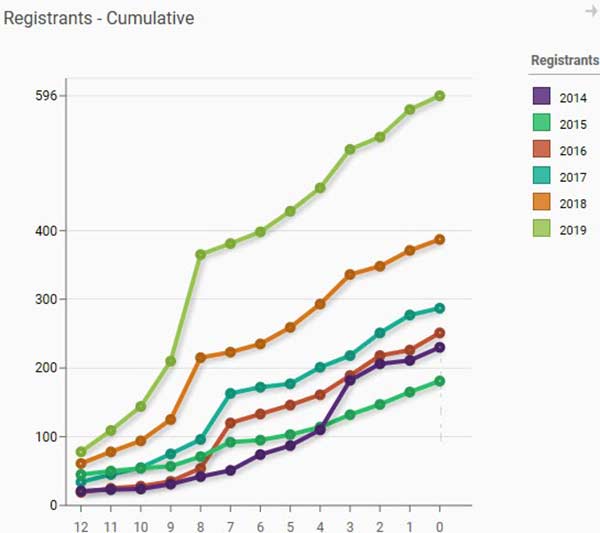
Snapshotting is ideal for providing historical comparisons of dues renewals and year-over-year financial results. One of my favorite visualizations is a weeks-out registration line-graph, compared to the same data in prior years. It is very easy to see if you are trending ahead of last year or whether you need to accelerate your marketing. Building a SQL report that compares this type of data against multiple years of history in a transaction system is a rather daunting task even if all the historical data is still available.
Other historical data that is useful to compare are changes in membership type, certification status, a member’s designation, or an email address. Often transactional systems do not keep the history of these data changes, which may be valuable to know when analyzing trends. Without snapshotting, this history may be just lost.
Our current snapshotting methodology in Nucleus includes storing multiple versions of the data – which works great because our technology handles large datasets easily. But, our future direction will be much more efficient and elegant – akin to “Time Machine” on the Mac or a source control system for code (only for data changes). This future direction is possible because of our investment in a pure data lake and “big data” technology, which supports this type of versioning.
While creating snapshots of your data and loading it into a data analytics tool isn’t rocket science, it is a fundamental capability that helps you better track member engagement and identify trends that will help you run your business better. Using a data analytics tool like Nucleus makes snapshotting easy; I sure wish I knew that back at the beginning of my career.


