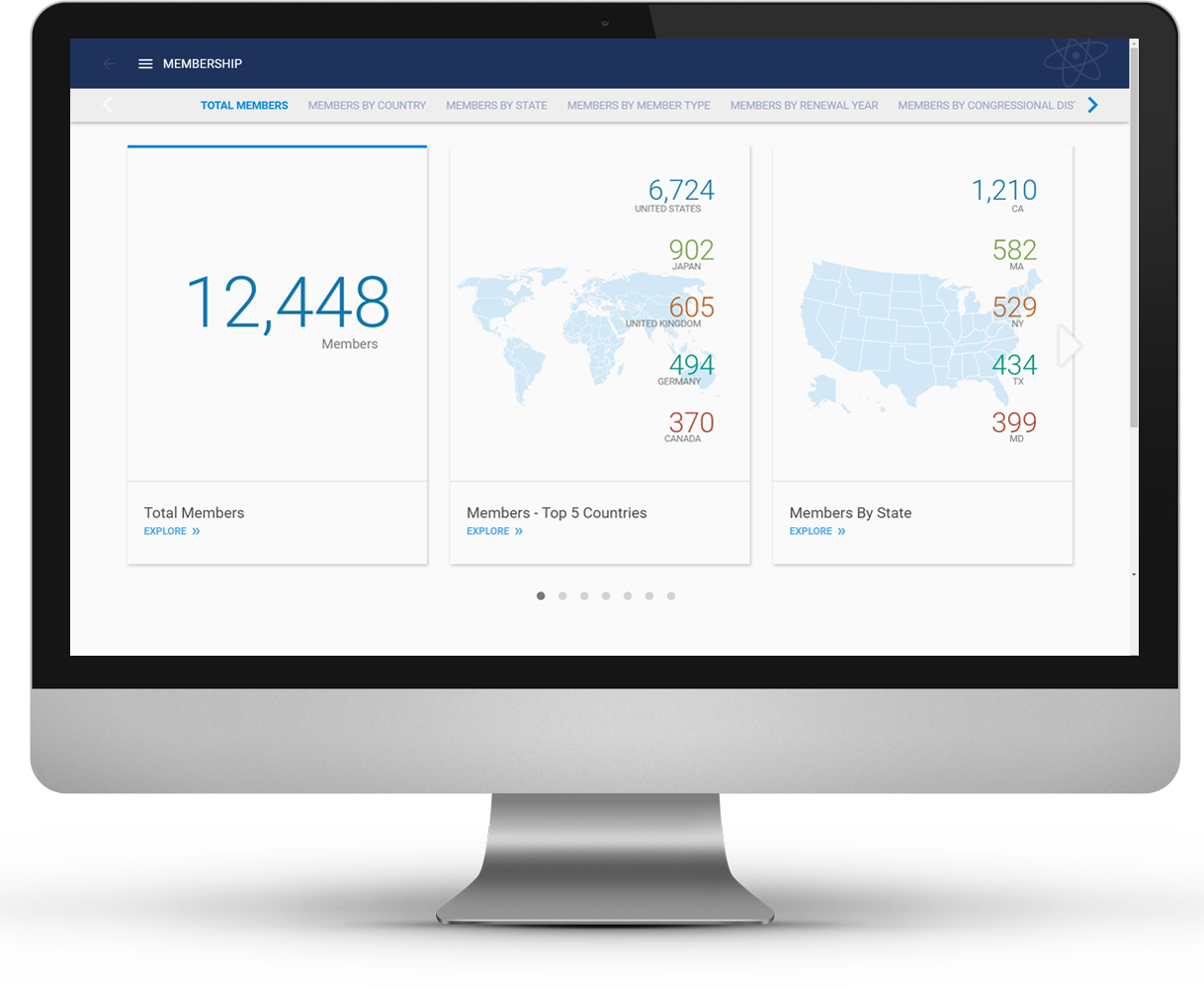
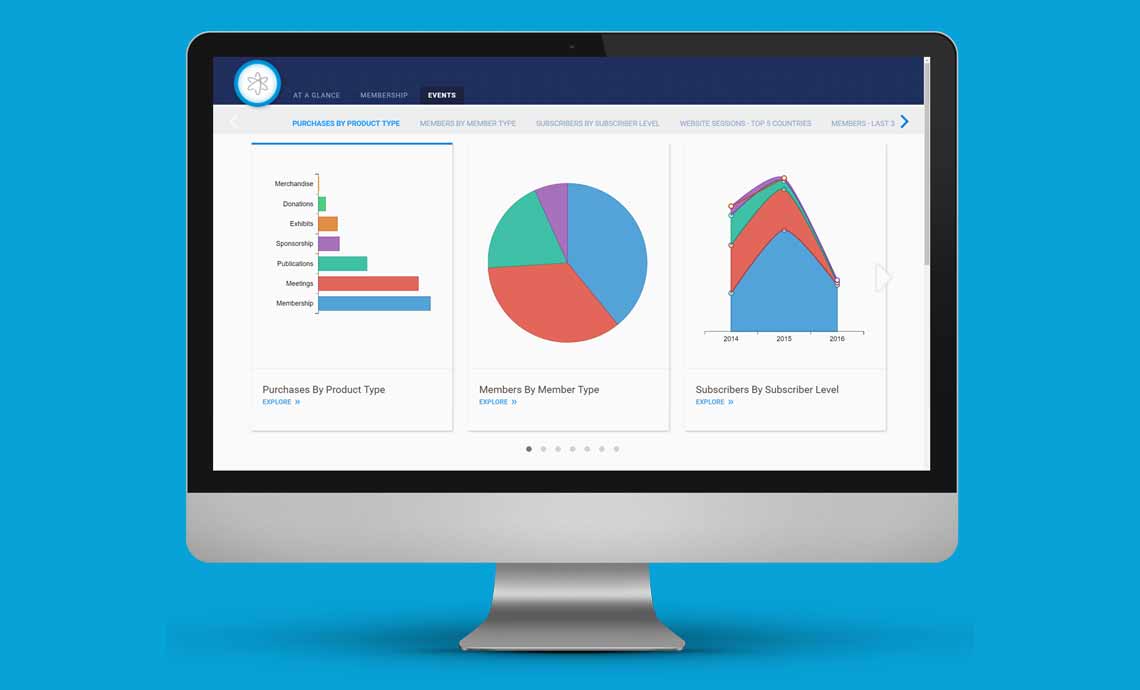
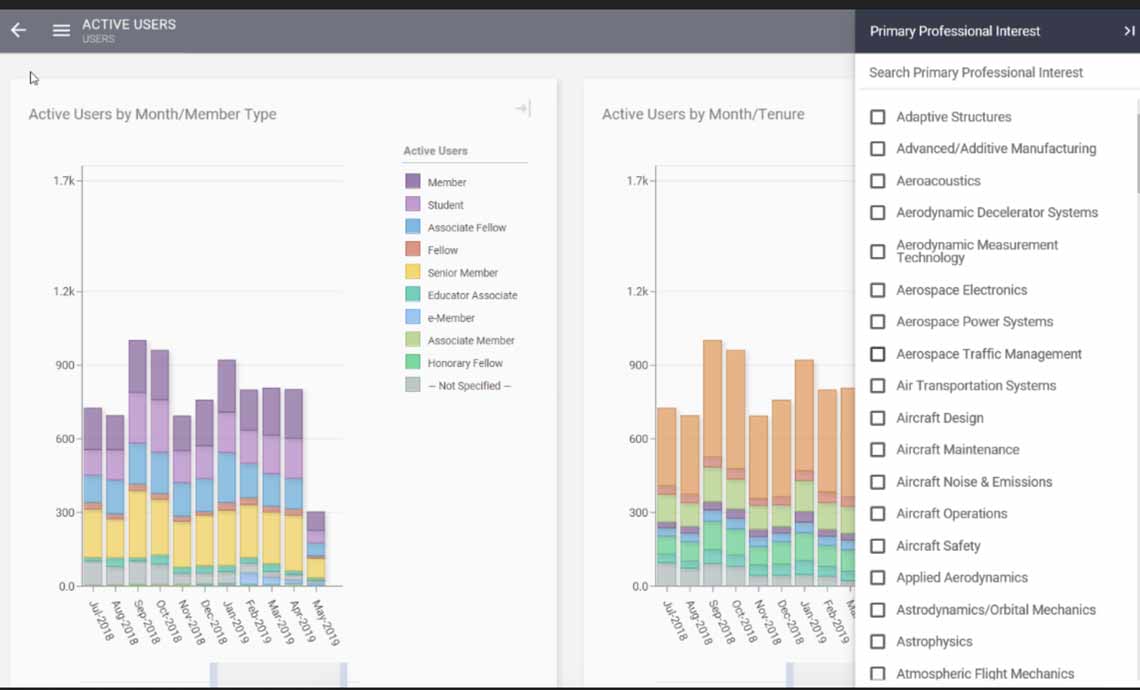
You get why data is important, and you’re serious about transforming your organization into a culture that embraces data-informed decision-making. Carpe datum!
When evaluating data analytics technology, it’s tempting to focus exclusively on the front-end design and usability, but how you store the data has major implications too. Begin forming your strategy by understanding the options and tradeoffs.
Most associations don’t have the resources, expertise, or time to undertake building data storage in-house and so they typically choose between outsourcing two common approaches: a data warehouse or a data lake. Whichever path you select will set strong parameters for what data you can store and how it can be used and visualized.
Let’s draw on some established definitions of each and then we’ll dive into why it matters:
- A data warehouse is a “central repository of integrated data from one or more disparate sources. They store current and historical data and are used for creating trending reports for senior management reporting such as annual or quarterly comparisons.”
Data warehouses are a traditional option that require substantial up-front time, cost, and effort identifying the appropriate data sources, understanding business processes, profiling data, and then building out infrastructure accordingly. They can also be difficult to scale.
- A data lake is “a storage repository that holds a vast amount of raw data in its native format, including structured, semi-structured, and unstructured data. The data structure and requirements are not defined until the data is needed” according to TechTarget.
Data lakes were created as a direct response to companies’ need to handle the increasing quantity and diversity of data available while delivering more accurate analytics and customer insights.
Here’s a table that compares these two options:
| Data Warehouse | Data Lake | |
| Supported Data Types | All data must be structured. | Supports diverse content: structured, semi-structured, and unstructured data. |
| Data Processing | Data must be highly transformed before it is loaded. This is known as schema-on-write. | Data is loaded in its native format and is only transformed when it is to be used. This is known as schema-on-read. |
| Data Agility | Data must have a pre-defined structure and purpose which limits the ability to use the stored data for new purposes and makes change management difficult and expensive. | ALL data is loaded which allows the data to be used for new purposes with minimal additional cost or effort. |
| Infrastructure & Scalability | Built on more specialized hardware which becomes more expensive and difficult to scale for large data sets. | Built on less expensive, commoditized hardware that can easily scale out to handle even the largest data sets. |
| Cost & Time-To-Value | Requires a significant upfront investment of time and money to identify data sources, understand business processes, profile data, and build infrastructure. Also has significant ongoing costs to include new data or ask new questions. | Less expensive and shorter startup time because the data structure and requirements are not defined until the data needs to be used. |
Given today’s data climate and the clear trends for the future – the generation, collection, and analysis of more and more data, both structured and unstructured — it is clear that the core of an association’s data analytics solution must be capable of quickly and affordably adapting to new data sources and analyses while scaling to handle increasingly large and varied data sets.
As the comparison above highlights, a data lake-based approach is the preferred choice when presented with these criteria and we recommend this route whether your organization is just starting a data analytics initiative or even if you have already invested in a data warehouse. By transitioning your data warehouse into a feed for the data lake, you can start to realize the benefits of a data lake while still leveraging your initial investment.
Neither a data lake (nor a data warehouse) is by itself a complete data analytics solution – for example, our own cloud data lake is just one piece of our Nucleus data platform – but starting with a data lake will provide your organization with the agile and affordable foundation to start you on the path to success.
To see a demo of a complete data lake-backed solution, request a Nucleus demo.