ca·non·i·cal
kəˈnänək(ə)l/
-conforming to a general rule or acceptable procedure
Recently we were working on a U.S.A. map visualization for one of our Nucleus Alpha program customers that overlaid dues vs. non-dues revenue by U.S. county. It’s pretty nifty and looks like this:
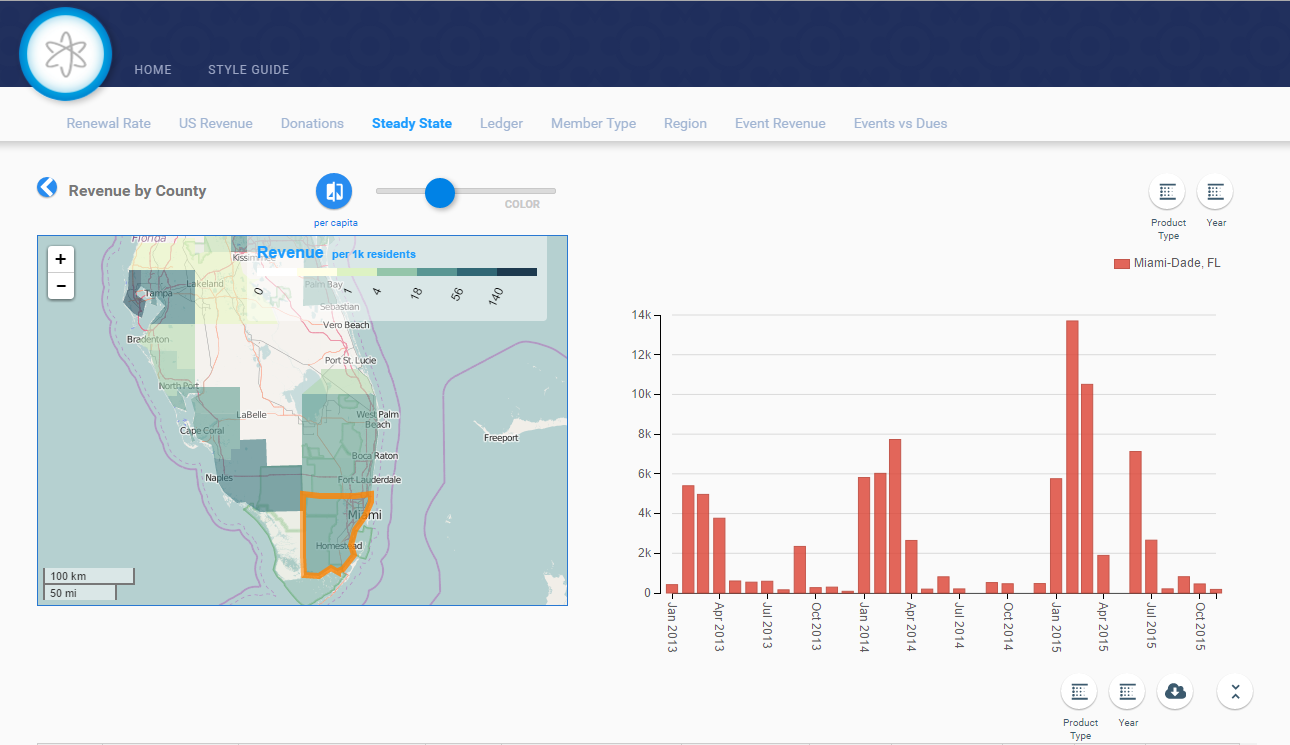
However, we weren’t initially getting the results we expected because we were pulling the county name directly out of the AMS database. We quickly realized that this wasn’t the best solution because of inconsistent data entry, spelling mistakes and case-sensitivity issues. Apparently, at some point actual humans were allowed to enter this piece of data into the AMS, and big shocker, mistakes were made.
For example, we had:
Miami-dade
Miami-Dade
miami-dade
Miami-Date
Miami Dade
For the record, the correct name is “Miami-Dade” which is a county you have heard of due to its prominence in a certain past presidential election cycle and proclivity for “hanging chads.” By the way, we also have a Chad here at Gravitate Solutions, he’s our resident data sciences guru and an all-around swell guy to “hang” with. But I digress…
Getting back to our data quality problem, after a brief discussion of the level of effort to write cleanup scripts (what happens when you title case “Miami-Dade”? uh-oh, you get “Miami-dade”), tweak our ETL process, etc., we ultimately decided that the AMS was not the canonical source for the regional data we needed and instead decided to download a free and publically available dataset from the U.S. Census Bureau that gave us not only a consistent and correct listing of all U.S. counties, but also a wealth of other useful data that we were able to incorporate into our visualization. For example, we could now show revenue density by county on a per capita basis. An added bonus that made our customer happy and made us feel good about ourselves was that we were able to deliver more value to our customer sooner by avoiding the time consuming trial and error of having to scrub and cleanse the data in the AMS (though we believe that to be a worthy exercise).
In summary, by working smarter and using a canonical source, we were able to quickly solve our data quality problem and leverage open data to improve our overall work product.


